万物容器化…
docker in docker
- 既然已经有了kvm in kvm,那么docker也是需要能够嵌套虚拟化的;
- 脑洞:how about kvm in docker?
- 自己打算基于centos镜像构建docker in docker镜像,发现在容器内创建容器需要获取root权限,加上–privileged也没有解决,想到docker hub 官网上面肯定已经有造好的轮子,执行指令
docker search docker发现确实存在docker in docker 的镜像,docker pull docker。 - 使用docker in docker 基础镜像:
docker run -it --privileged --name some-docker -d docker:dind docker logs some-docker docker run -it --rm --link some-docker:docker docker sh # 发现已经进入到容器内部的命令行,测试一下: docker run -it --name busybox busybox hostname # 发现容器id和some-docker的id不一样,表示已经进入了docker 的 dicker镜像 - 之后可以重复这个过程,也就是说只要你愿意可以建立多层docker in docker~
hadoop on docker
- 大象在鲸鱼上跳舞:
#拉取镜像,这里拉取的别人的精简版hadoop镜像,没有使用官网镜像,该镜像的初始版本还得过奖 sudo docker pull kiwenlau/hadoop:1.0 #下载启动hadoop容器集群源码: git clone https://github.com/kiwenlau/hadoop-cluster-docker cd hadoop-cluster-docker/ #创建docker网络,目的是为了hadoop的master和slave可以使用这个网络,进行服务发现,相当于DNS服务器 sudo docker network create --driver=bridge hadoop #运行docker容器: ./start-container.sh #进入到hadoop-master容器中,启动hadoop: ./start-hadoop.sh - 启动hadoop集群后的输出信息:
Starting namenodes on [hadoop-master] hadoop-master: Warning: Permanently added 'hadoop-master,172.18.0.2' (ECDSA) to the list of known hosts. hadoop-master: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-hadoop-master.out hadoop-slave2: Warning: Permanently added 'hadoop-slave2,172.18.0.4' (ECDSA) to the list of known hosts. hadoop-slave1: Warning: Permanently added 'hadoop-slave1,172.18.0.3' (ECDSA) to the list of known hosts. hadoop-slave2: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-hadoop-slave2.out hadoop-slave1: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-hadoop-slave1.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts. 0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-hadoop-master.out starting yarn daemons starting resourcemanager, logging to /usr/local/hadoop/logs/yarn--resourcemanager-hadoop-master.out hadoop-slave2: Warning: Permanently added 'hadoop-slave2,172.18.0.4' (ECDSA) to the list of known hosts. hadoop-slave1: Warning: Permanently added 'hadoop-slave1,172.18.0.3' (ECDSA) to the list of known hosts. hadoop-slave2: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-hadoop-slave2.out hadoop-slave1: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-hadoop-slave1.out - 运行word-count案例:
root@hadoop-master:~# ./run-wordcount.sh 17/07/03 13:23:50 INFO client.RMProxy: Connecting to ResourceManager at hadoop-master/172.18.0.2:8032 17/07/03 13:23:51 INFO input.FileInputFormat: Total input paths to process : 2 17/07/03 13:23:52 INFO mapreduce.JobSubmitter: number of splits:2 17/07/03 13:23:53 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1499088095628_0001 17/07/03 13:23:53 INFO impl.YarnClientImpl: Submitted application application_1499088095628_0001 17/07/03 13:23:53 INFO mapreduce.Job: The url to track the job: http://hadoop-master:8088/proxy/application_1499088095628_0001/ 17/07/03 13:23:53 INFO mapreduce.Job: Running job: job_1499088095628_0001 17/07/03 13:24:30 INFO mapreduce.Job: Job job_1499088095628_0001 running in uber mode : false 17/07/03 13:24:30 INFO mapreduce.Job: map 0% reduce 0% 17/07/03 13:24:47 INFO mapreduce.Job: map 50% reduce 0% 17/07/03 13:24:48 INFO mapreduce.Job: map 100% reduce 0% 17/07/03 13:24:58 INFO mapreduce.Job: map 100% reduce 100% 17/07/03 13:24:59 INFO mapreduce.Job: Job job_1499088095628_0001 completed successfully 17/07/03 13:24:59 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=56 FILE: Number of bytes written=352398 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=258 HDFS: Number of bytes written=26 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=30737 Total time spent by all reduces in occupied slots (ms)=6406 Total time spent by all map tasks (ms)=30737 Total time spent by all reduce tasks (ms)=6406 Total vcore-milliseconds taken by all map tasks=30737 Total vcore-milliseconds taken by all reduce tasks=6406 Total megabyte-milliseconds taken by all map tasks=31474688 Total megabyte-milliseconds taken by all reduce tasks=6559744 Map-Reduce Framework Map input records=2 Map output records=4 Map output bytes=42 Map output materialized bytes=62 Input split bytes=232 Combine input records=4 Combine output records=4 Reduce input groups=3 Reduce shuffle bytes=62 Reduce input records=4 Reduce output records=3 Spilled Records=8 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=518 CPU time spent (ms)=7700 Physical memory (bytes) snapshot=710238208 Virtual memory (bytes) snapshot=2512601088 Total committed heap usage (bytes)=559415296 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=26 File Output Format Counters Bytes Written=26 input file1.txt: Hello Hadoop input file2.txt: Hello Docker wordcount output: Docker 1 Hadoop 1 Hello 2 - 通过网络访问hadoop-master容器和hadoop-slave容器:
http://host-ip:8088;访问存在于主节点的ResourceManager UI: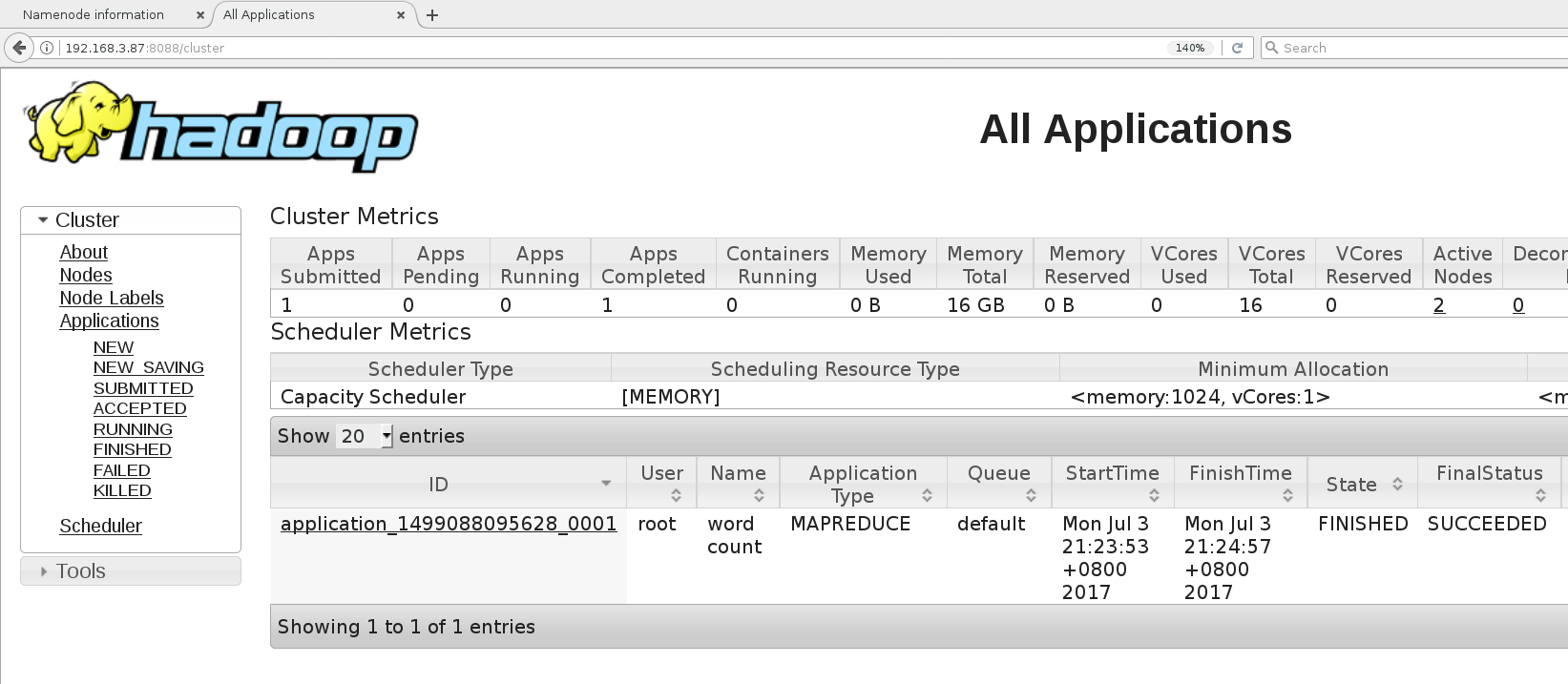
- 访问
http://host-ip:50070,查看从节点NameNode UI: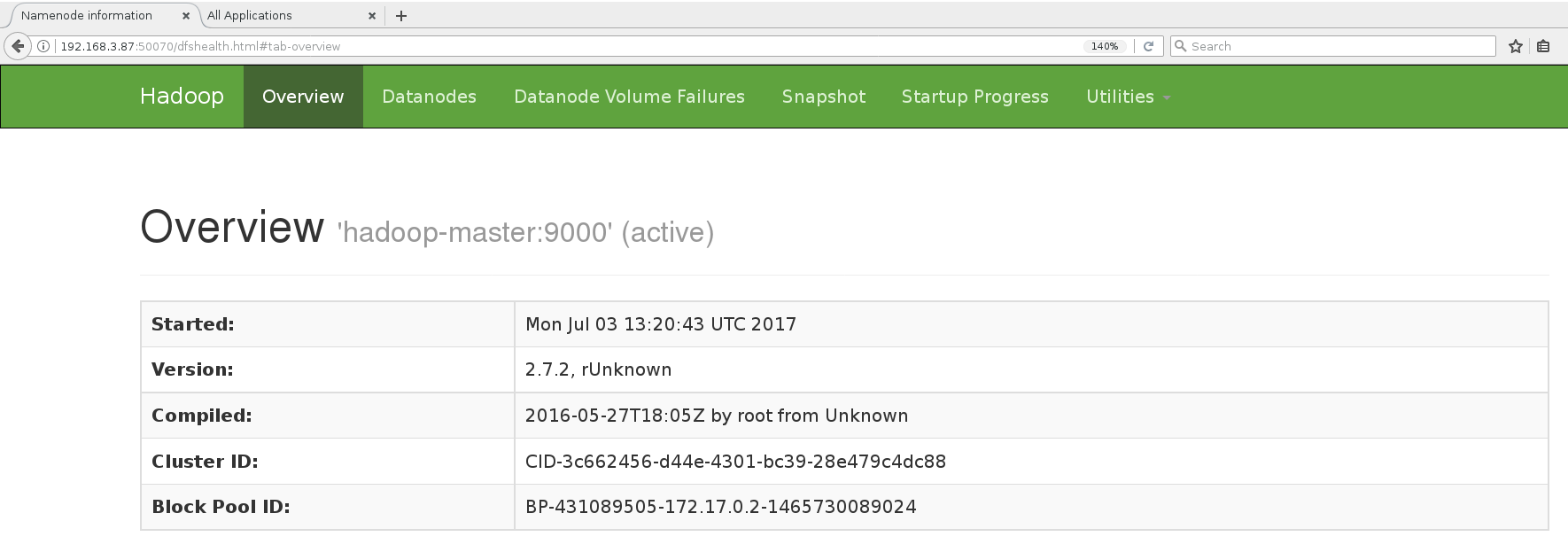
感想
- 容器化后应用使用的虚拟网络,管理容器集群所有容器应用的整套网络感觉不简单;
- 重复造dockerfile的轮子好像也没啥收获;
- 应用容器化是趋势;
参考
docker run docker
Docker in Docker!
基于Docker快速搭建多节点Hadoop集群
基于Docker搭建Hadoop集群之升级版